简介
Stable Diffusion WebUI是使用该算法的图形化界面。不借助WebUI也可以使用Stable Diffusion,但是要写python程序。图形界面中,最普及的是AUTOMATIC1111。当然网络上也有各式社区成员提供的自己写的WebUI,本质上功能都是一样的。但AUTOMATIC1111用的人多,能找到的信息多,功能全面,而且眼下更新速度很快。
在有了算法和图形化界面之后,你需要给算法提供一个模型。这个模型决定了画出来的画风是什么样子的,例如NovelAI就是Stable Diffusion的一个二次元向的模型。
ckpt文件是Stable Diffusion模型的文件格式,下载后,放置在根目录下的model文件夹里的,stable diffusion子文件夹里面。不同的模型是在不同的数据集上训练出来的。例如Waifu Diffusion是在Danbooru动漫图片库中训练出来的,训练的tag就是数据库中社区成员们贡献的tag。Danbooru的健全版是Safebooru。有的模型使用safetensor文件,可以和ckpt文件一样使用,一样也放到model文件夹里的stable diffusion子文件夹里面。
vae是variable autoencoder的意思。在Stable Diffusion WebUI的settings里面,stable diffusion那一栏,有一个“SD VAE”,在这里可以选择载入vae组分。使用vae组分可以让图片的色彩变得更好。
安装
这里推荐一些大佬的一键包,可以直接避免新手,或者不懂的以避免踩坑。
N卡的推荐秋葉aaaki的一键包NovelAI,方法简单,功能很全
详细使用方法可以视频链接:https://www.bilibili.com/video/BV1ne4y1V7QU/?spm_id_from=333.999.0.0&vd_source=e9c0a2c291f2a3a9ba6db8005ad1bb2d
下载NovelAI链接:链接:https://pan.baidu.com/s/1tCprxK_CUdwEn80AFpLoIw
AI 绘画 webui 版本整合包v3 (B站视频链接)
提取码:u612
开始
选择好模型,这里推荐从一个模型网站https://civitai.com/进行下载,下载后存放到目录:novelai-webui-aki-v3\models\Stable-diffusion
也可以在启动器左侧选择模型管理下载:

启动之前的配置:
选择好使用的显卡,显存大小,其他的参数可以先根据我的进行设置吗,勾选下启动完毕后浏览器打开
启动后页面如下: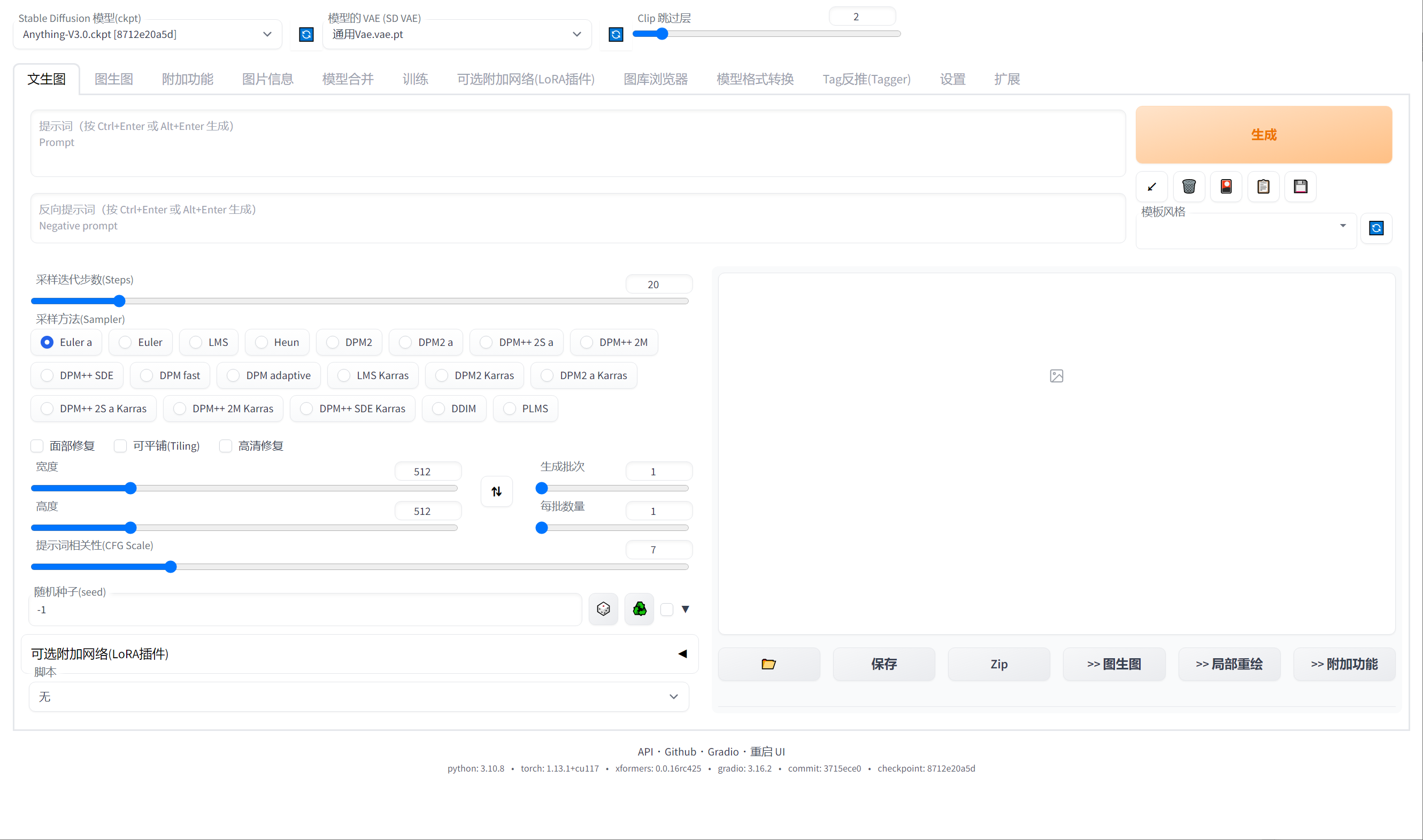
这个填写您需要生成的关键词,比如一个女孩,1girl
这里填写您不需要生成的关键词,比如一个男孩,1boy
- 注意:
- 可以不带{ }和[ ],
- 带{ }表示加强这个词的比重,
- [ ]表示减少这个词的比重
下面一些是采样选项,步数,采样方法,图片的分辨率,相关词性(上面填写的关键词),种子(生成不同的图片,默认随机,需要一样的,可以填写指定参数)
点击生成,开始制作
进度完成之后,会返回图片在web-ui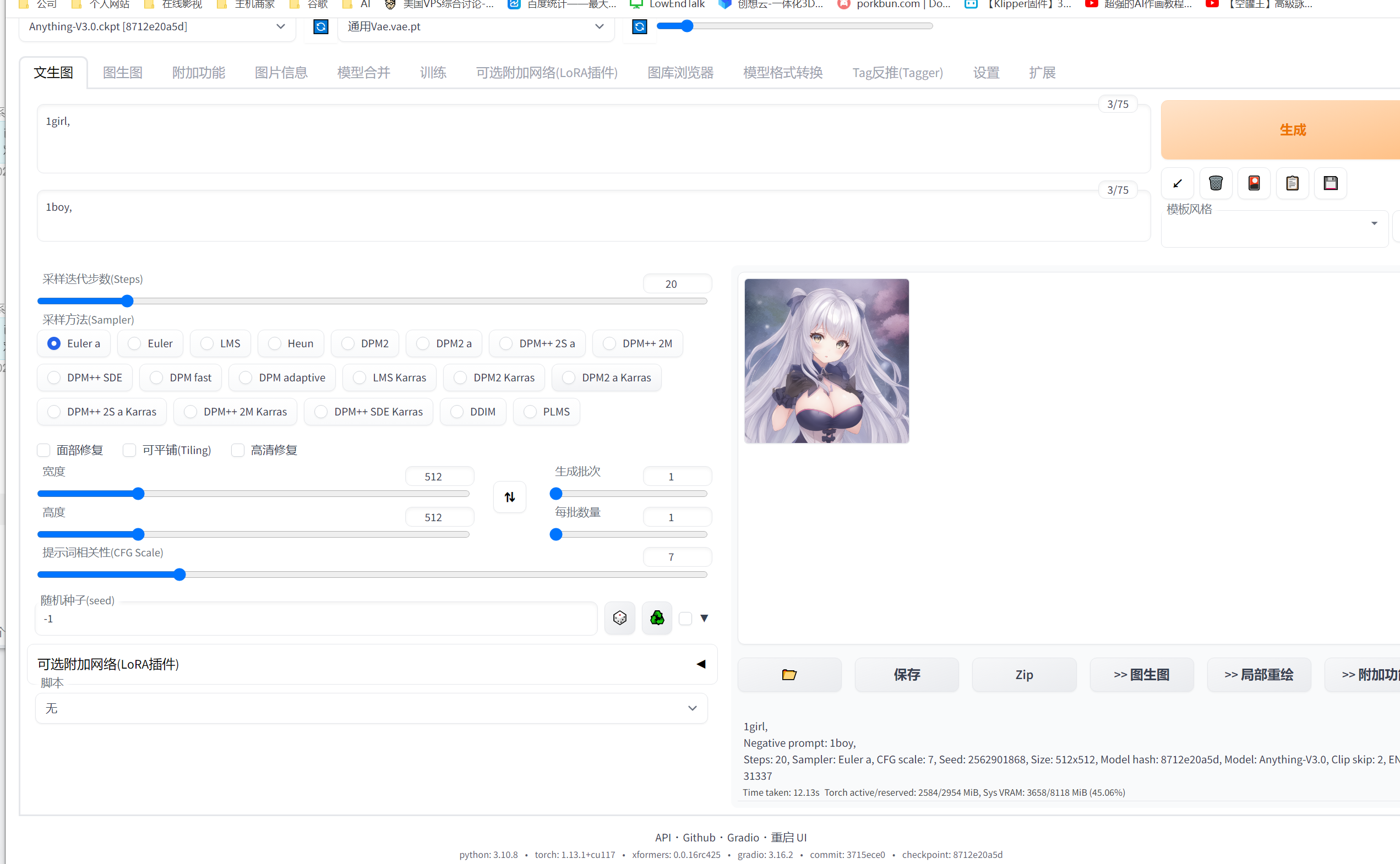
注意底部有关于图片的具体参数:
1girl,
Negative prompt: 1boy,
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 2562901868, Size: 512x512, Model hash: 8712e20a5d, Model: Anything-V3.0, Clip skip: 2, ENSD: 31337
技巧
选择
可以到网站:civitai,找到参考模型和图片,点击图片查看详细参数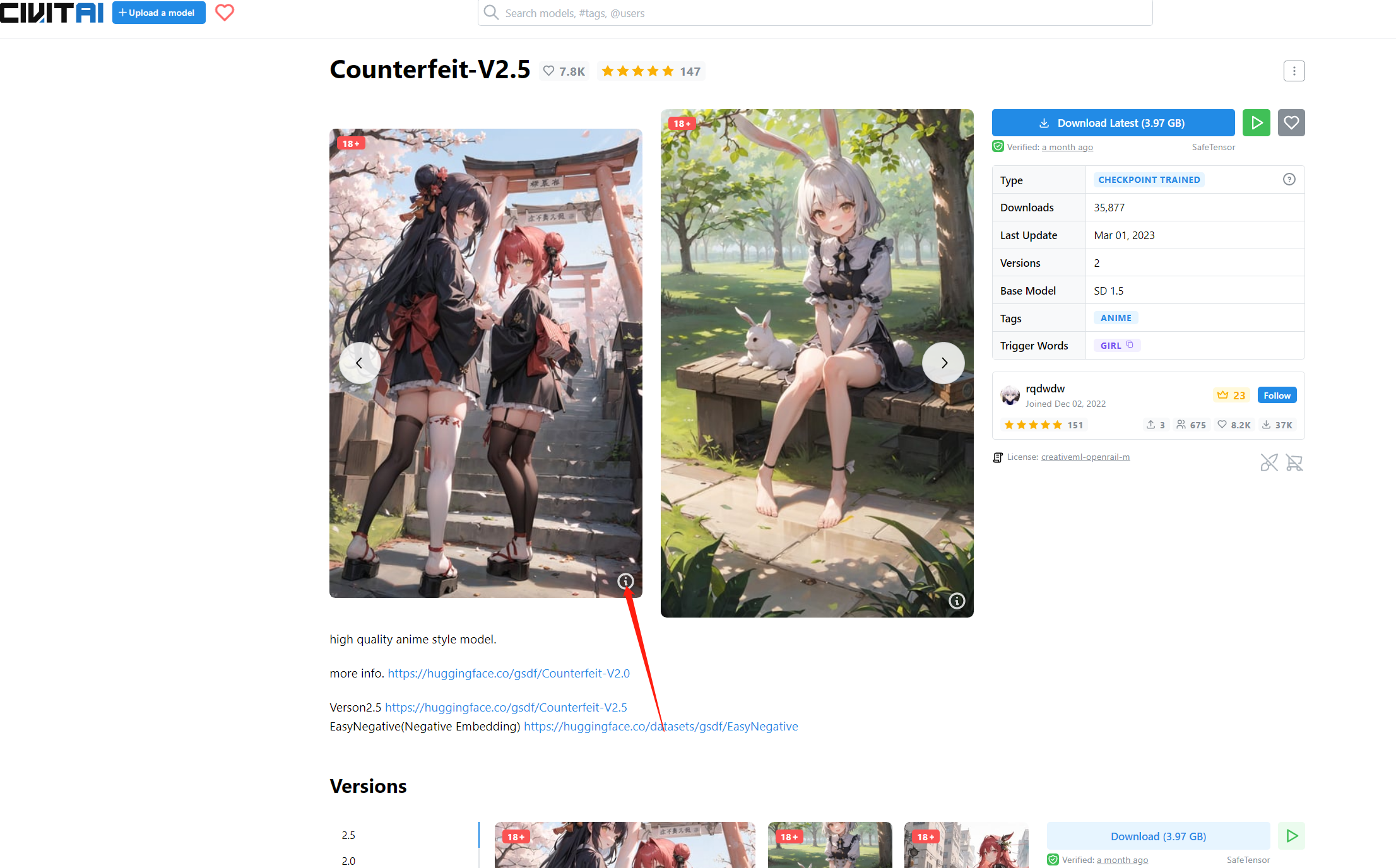
选择COPY
复制到提示词第一个行,点击生成底部的箭头。会自动填充图片的生成方法
生成后图片如下:
NovelAI的缺点和主要鉴别依据
NovelAI程序的学习制图缺点就是:
1、手脚四肢不容易做完美,所以做出来的图可能没有四肢。
2、鼻子目前学习的还不够好,大部分做出来的图片都是一样的鼻子特点,往往是没有鼻子或者鼻子上面有个白色圈点,可以观察一下对边看看。
结尾
还有很多的教程和方法,待后续慢慢完善,有兴趣的可以在B站找到资料,以上的只推荐N卡使用,AMD显卡请移步后续我写的另一个教程

3 条评论
555
555
555